38 variational autoencoder for deep learning of images labels and captions
PDF Variational Autoencoder for Deep Learning of Images, Labels and Captions A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used PDF Variational Autoencoder for Deep Learning of Images, Labels and Captions Title: Variational Autoencoder for Deep Learning of Images, Labels and Captions Author: Yunchen Pu , Zhe Gan , Ricardo Henao , Xin Yuan , Chunyuan Li , Andrew Stevens and Lawrence Carin
GitHub - DirtyHarryLYL/Transformer-in-Vision: Recent … (arXiv 2022.07) A Variational AutoEncoder for Transformers with Nonparametric Variational Information Bottleneck, (arXiv 2022.07) Online Continual Learning with Contrastive Vision Transformer, (arXiv 2022.07) Retrieval-Augmented Transformer for Image Captioning,

Variational autoencoder for deep learning of images labels and captions
PDF Variational Autoencoder for Deep Learning of Images, Labels and Captions A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution Variational Autoencoder for Deep Learning of Images, Labels and Captions Variational Autoencoder for Deep Learning of Images, Labels and Captions Yunchen Pu, Zhe Gan, Ricardo Henao, Xin Yuan, Chunyuan Li, Andrew Stevens, Lawrence Carin A novel variational autoencoder is developed to model images, as well as associated labels or captions. Reviews: Variational Autoencoder for Deep Learning of Images, Labels ... Reviews: Variational Autoencoder for Deep Learning of Images, Labels and Captions NIPS 2016 Mon Dec 5th through Sun the 11th, 2016 at Centre Convencions Internacional Barcelona Reviewer 1 Summary This paper presents a new variational autoencoder (VAE) for images, which also is capable of predicting labels and captions.
Variational autoencoder for deep learning of images labels and captions. Variational Autoencoder for Deep Learning of Images, Labels and Captions A novel variational autoencoder is developed to model images, as well as associated labels or captions, and a new semi-supervised setting is manifested for CNN learning with images; the framework even allows unsupervised CNN learning, based on images alone. A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative ... A Survey on Deep Learning for Multimodal Data Fusion May 01, 2020 · A stacked autoencoder (SAE) is a typical deep learning model of the encoder-decoder architecture (Michael ... component is introduced to adaptively combine input and states. Jang, Seo, and Kang designed the semantic variational recurrent autoencoder to model the global text features in a sentence ... To generate captions for images, ... Variational Autoencoder for Deep Learning of Images, Labels and Captions CiteSeerX - Document Details (Isaac Councill, Lee Giles, Pradeep Teregowda): Abstract A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to ... Plant diseases and pests detection based on deep learning: a … Feb 24, 2021 · Pu Y, Gan Z, Henao R, et al. Variational autoencoder for deep learning of images, labels and captions [EB/OL]. 2016–09–28. arxiv:1609.08976. Oppenheim D, Shani G, Erlich O, Tsror L. Using deep learning for image-based potato tuber disease detection. Phytopathology. 2018;109(6):1083–7. Article Google Scholar
DeepTCR is a deep learning framework for revealing sequence ... - Nature Mar 11, 2021 · A variational autoencoder provides superior antigen-specific clustering ... Y. et al. Variational autoencoder for deep learning of images, labels and captions. Adv. Neural Inf. Process. Syst. 29 ... Image classification | TensorFlow Core Aug 12, 2022 · This is a batch of 32 images of shape 180x180x3 (the last dimension refers to color channels RGB). The label_batch is a tensor of the shape (32,), these are corresponding labels to the 32 images. You can call .numpy() on the image_batch and labels_batch tensors to convert them to a numpy.ndarray. Configure the dataset for performance Variational Autoencoder for Deep Learning of Images, Labels and Captions Since the framework is capable of modeling the image in the presence/absence of associated labels/captions, a new semi-supervised setting is manifested for CNN learning with images; the framework even allows unsupervised CNN learning, based on images alone. PDF Abstract NeurIPS 2016 PDF NeurIPS 2016 Abstract Code Edit No code implementations yet. Variational autoencoder for deep learning of images, labels and ... Variational autoencoder for deep learning of images, labels and captions Pages 2360-2368 ABSTRACT References Comments ABSTRACT A novel variational autoencoder is developed to model images, as well as associated labels or captions.
Variational Autoencoder for Deep Learning of Images, Labels and Captions Pu et al. [63] designed a variational autoencoder for deep learning applied to classifying images, labels, and captions. A CNN was used as the encoder to distribute the latent features to... robmarkcole/satellite-image-deep-learning - GitHub deeppop-> Deep Learning Approach for Population Estimation from Satellite Imagery, also on Github; Estimating telecoms demand in areas of poor data availability-> with papers on arxiv and Science Direct; satimage-> Code and models for the manuscript "Predicting Poverty and Developmental Statistics from Satellite Images using Multi-task Deep ... arXiv.org e-Print archive arXiv.org e-Print archive Proceedings of the 2021 Conference on Empirical Methods in … While self-training is potentially an effective method to address this issue, the pseudo-labels it yields on unlabeled data could induce noise. In this paper, we use two means to alleviate the noise in the pseudo-labels. One is that inspired by the curriculum learning, we refine the conventional self-training to progressive self-training.
A deep-learning-based unsupervised model on esophageal ...
Text-to-image model - Wikipedia Before the rise of deep learning, attempts to build text-to-image models were limited to collages by arranging existing component images, such as from a database of clip art.. The inverse task, image captioning, was more tractable and a number of image captioning deep learning models came prior to the first text-to-image models. The first modern text-to-image model, alignDRAW, …
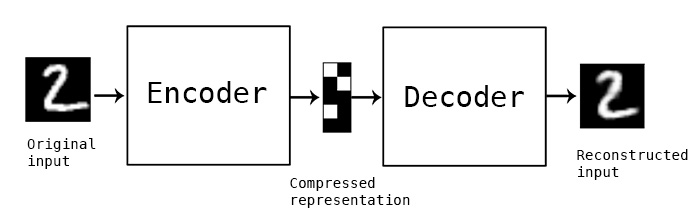
Building Autoencoders in Keras
Smart Video Generation from Text Using Deep Neural Networks Dec 29, 2021 · The aim of the project is to build a deep learning pipeline that accepts text descriptions to produce video descriptions that are attractive and unique. The short movie clip generation project uses GAN video generation, a deep learning algorithm that produces unique and realistic video content by pinning two neural networks against each other.
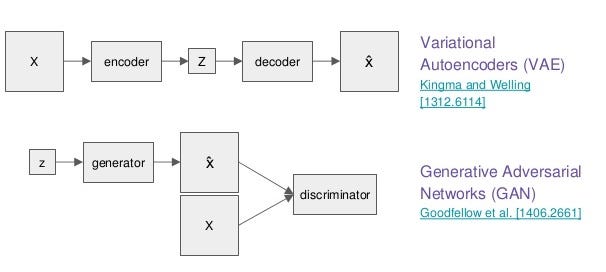
What a Disentangled Net We Weave: Representation Learning in ...
Variational Autoencoder for Deep Learning of Images, Labels and Captions PDF - A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN features/code.

VAE: giving your Autoencoder the power of imagination
Variational Autoencoder for Deep Learning of Images, Labels and Captions A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN ...

Recent advances and applications of deep learning methods in ...
2017 IEEE International Conference on Computer Vision (ICCV) Cross-Modal Deep Variational Hashing pp. 4097-4105. ... Learning Deep Neural Networks for Vehicle Re-ID with Visual-spatio-Temporal Path Proposals pp. 1918-1927. Learning from Noisy Labels with Distillation pp. 1928-1936. DSOD: Learning Deeply Supervised Object Detectors from Scratch pp. 1937-1945.
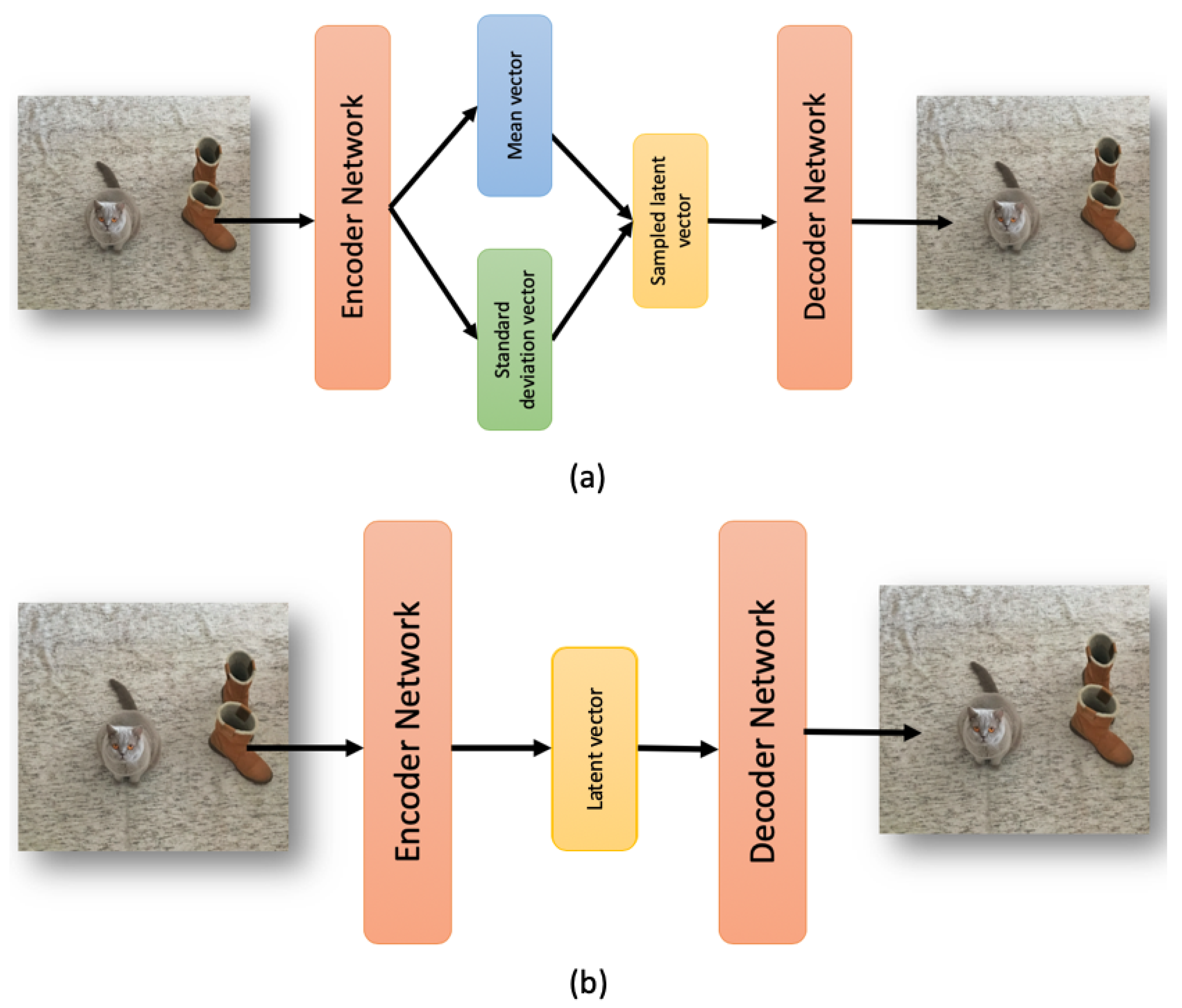
Sensors | Free Full-Text | Detecting Respiratory Pathologies ...
Variational Autoencoder for Deep Learning of Images, Labels and Captions Corpus ID: 2665144; Variational Autoencoder for Deep Learning of Images, Labels and Captions @inproceedings{Pu2016VariationalAF, title={Variational Autoencoder for Deep Learning of Images, Labels and Captions}, author={Yunchen Pu and Zhe Gan and Ricardo Henao and Xin Yuan and Chunyuan Li and Andrew Stevens and Lawrence Carin}, booktitle={NIPS}, year={2016} }

Train Variational Autoencoder (VAE) to Generate Images ...
Variational Autoencoder for Deep Learning of Images, Labels and Captions The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN features/code.
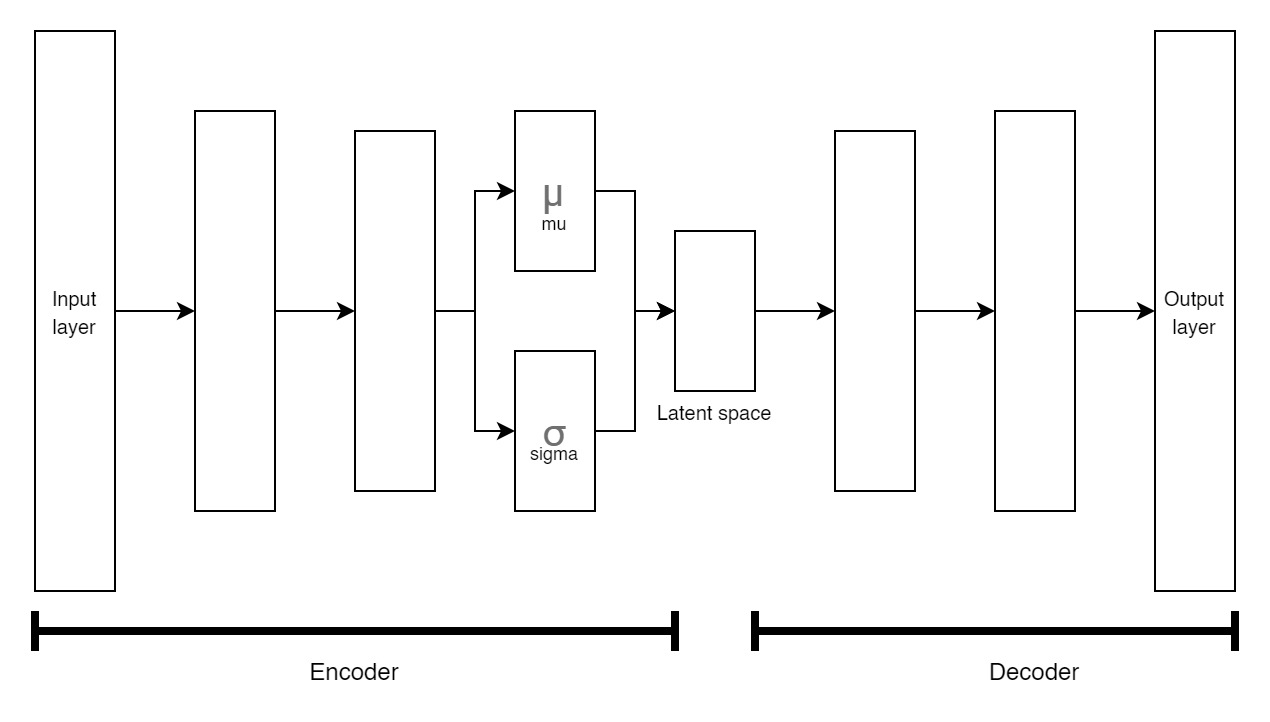
![Autoencoders in Deep Learning: Tutorial & Use Cases [2022]](https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/60e424b06f61a263edba1fe6_diagrammetic.png)
Autoencoders in Deep Learning: Tutorial & Use Cases [2022]
Reviews: Variational Autoencoder for Deep Learning of Images, Labels ... Reviews: Variational Autoencoder for Deep Learning of Images, Labels and Captions NIPS 2016 Mon Dec 5th through Sun the 11th, 2016 at Centre Convencions Internacional Barcelona Reviewer 1 Summary This paper presents a new variational autoencoder (VAE) for images, which also is capable of predicting labels and captions.
Using Variational Autoencoder (VAE) to Generate New Images ...
Variational Autoencoder for Deep Learning of Images, Labels and Captions Variational Autoencoder for Deep Learning of Images, Labels and Captions Yunchen Pu, Zhe Gan, Ricardo Henao, Xin Yuan, Chunyuan Li, Andrew Stevens, Lawrence Carin A novel variational autoencoder is developed to model images, as well as associated labels or captions.

Variational Autoencoder for Deep Learning of Images, Labels ...
PDF Variational Autoencoder for Deep Learning of Images, Labels and Captions A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution

How VAEs Can Flourish In Any Machine Learning Setting
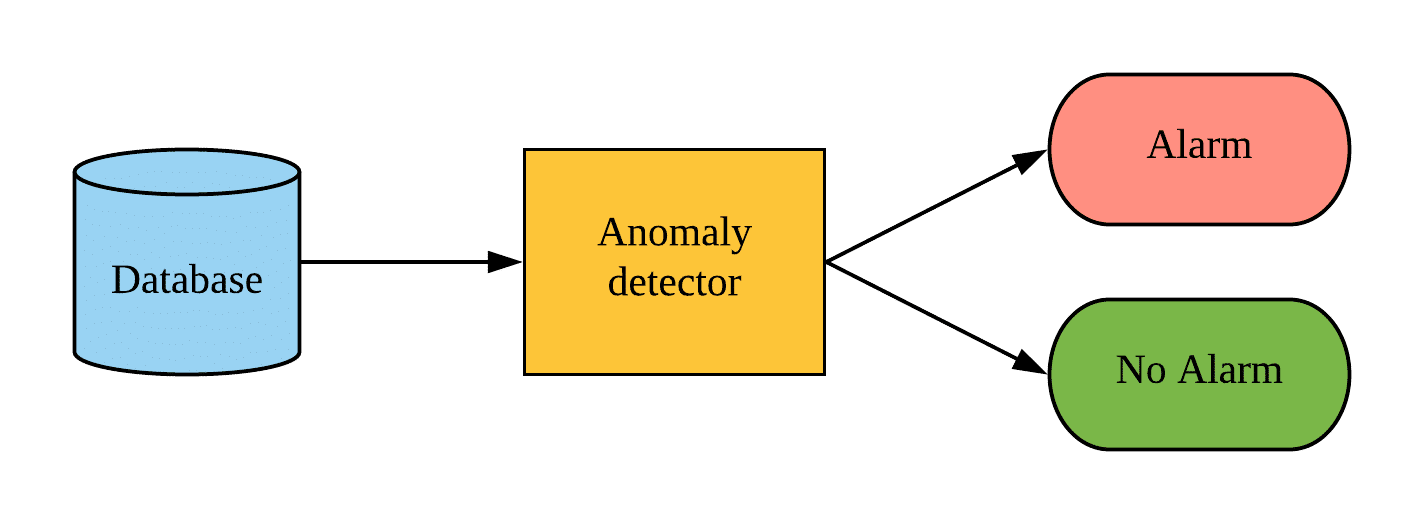
Time series Anomaly Detection using a Variational Autoencoder ...

Deep Learning and Infrared Spectroscopy: Representation ...

Guided Variational Autoencoder for Disentanglement Learning ...

Applied Deep Learning - Part 3: Autoencoders | by Arden ...
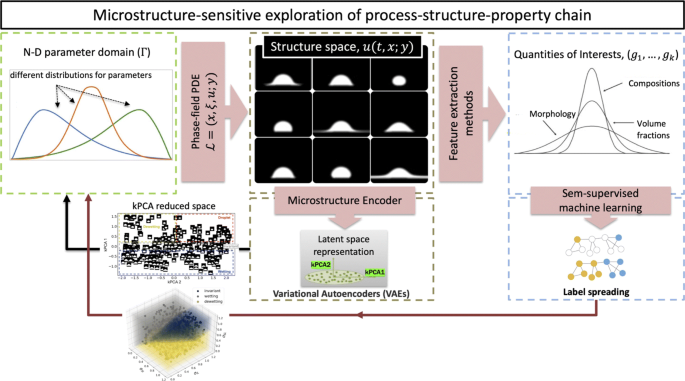
Machine learning-assisted high-throughput exploration of ...
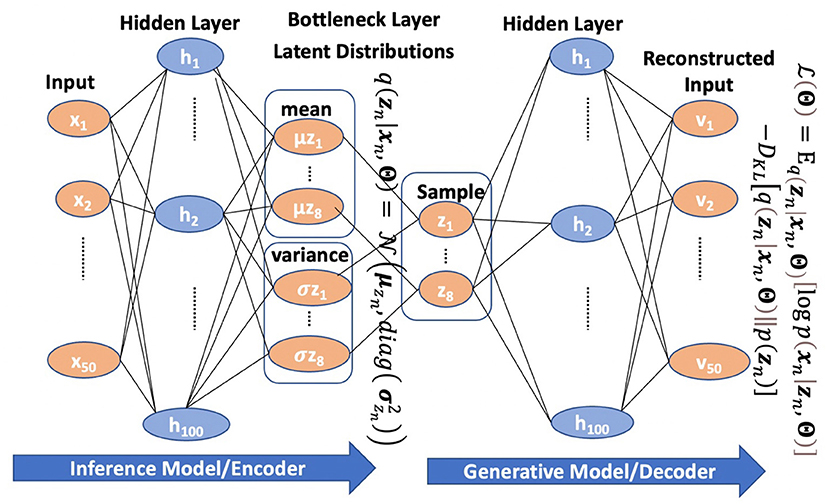
Frontiers | Exploring Factor Structures Using Variational ...

Methods: (A) VAE/MMD-VAE architecture consists of an encoder ...
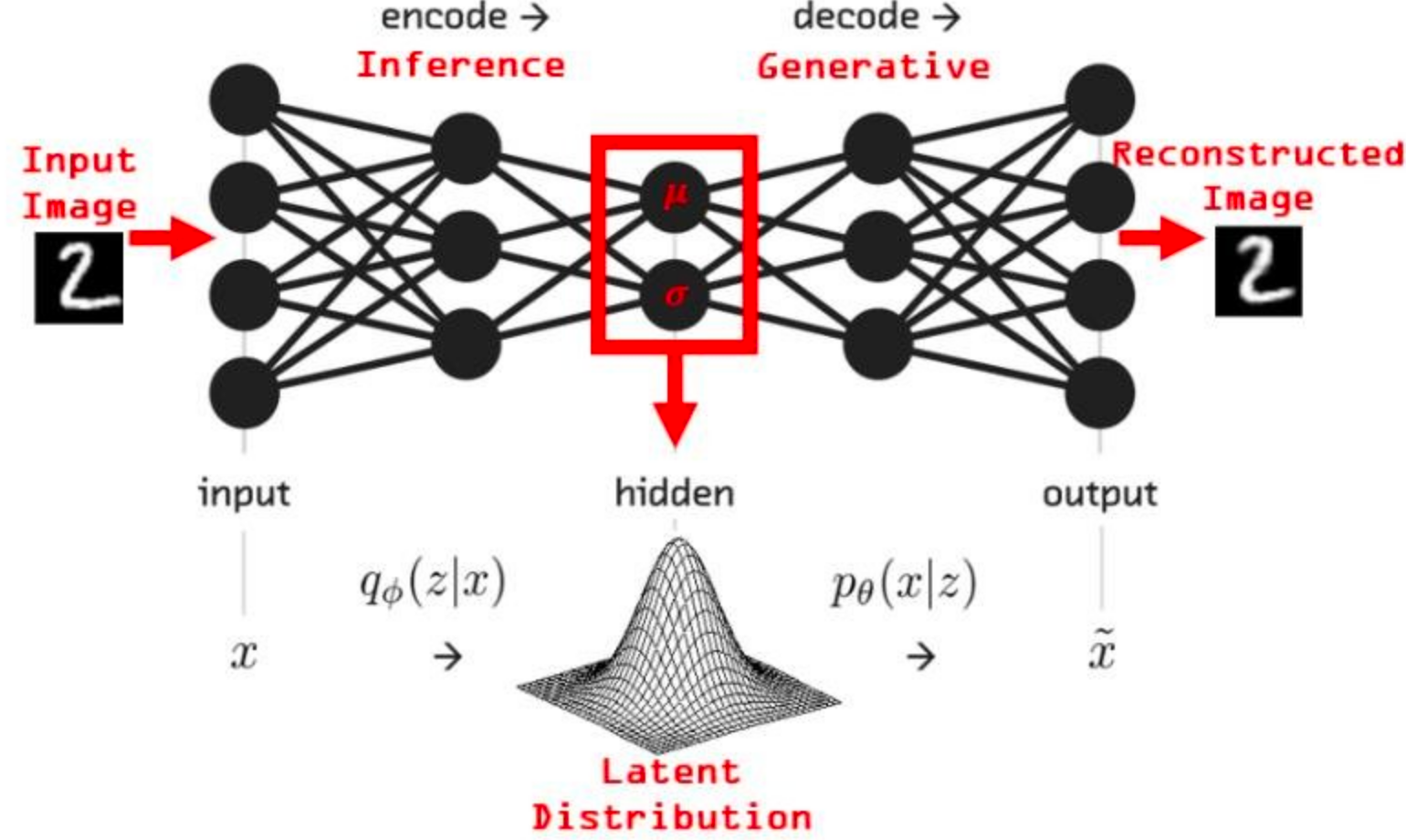
Generate music with Variational AutoEncoder | Kaggle

Variational Autoencoder for Deep Learning of Images, Labels ...
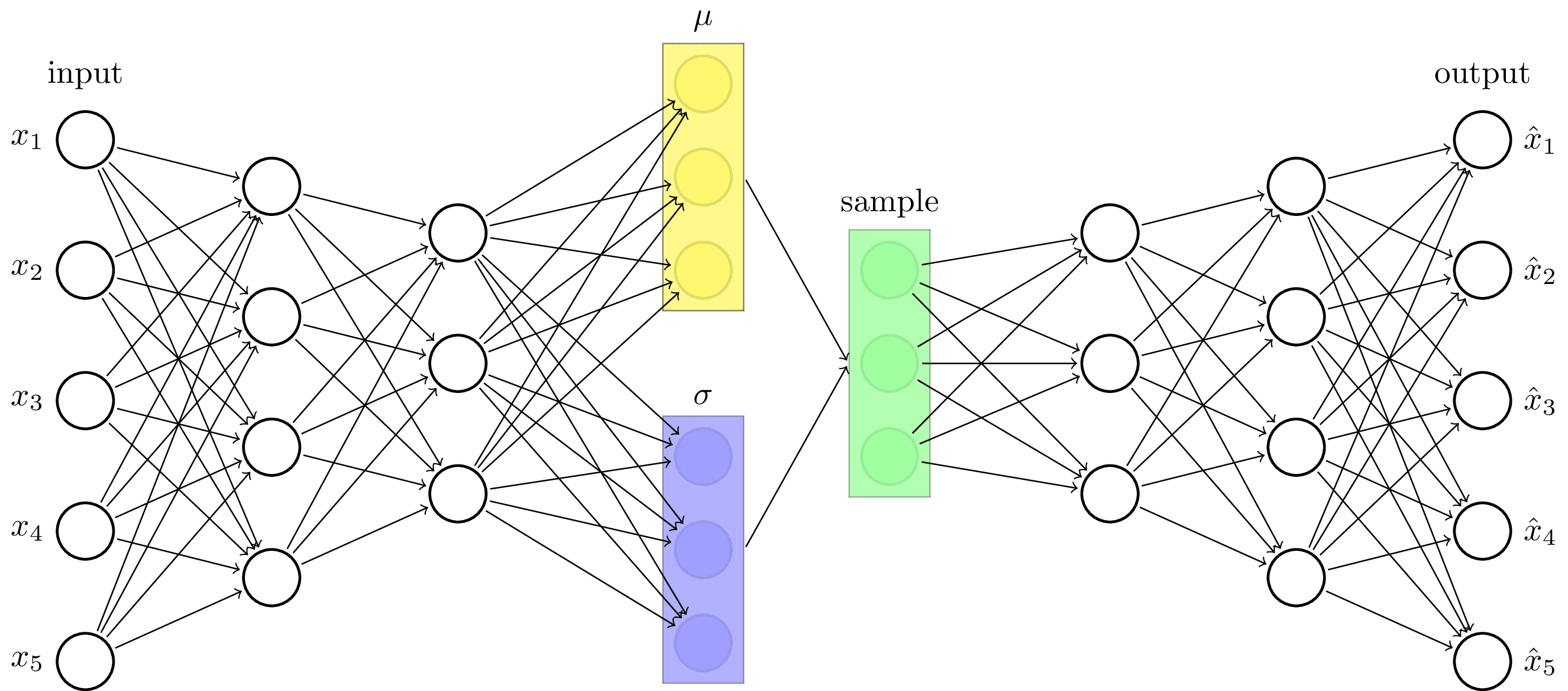
Variational Auto Encoder Architecture – TikZ.net
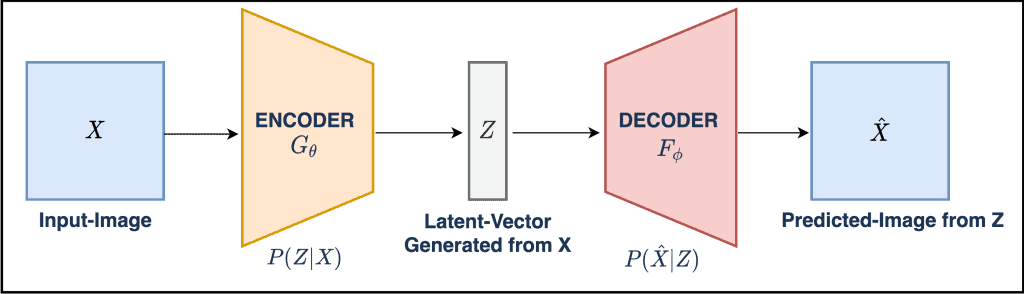
Variational Autoencoder in TensorFlow (Python Code)
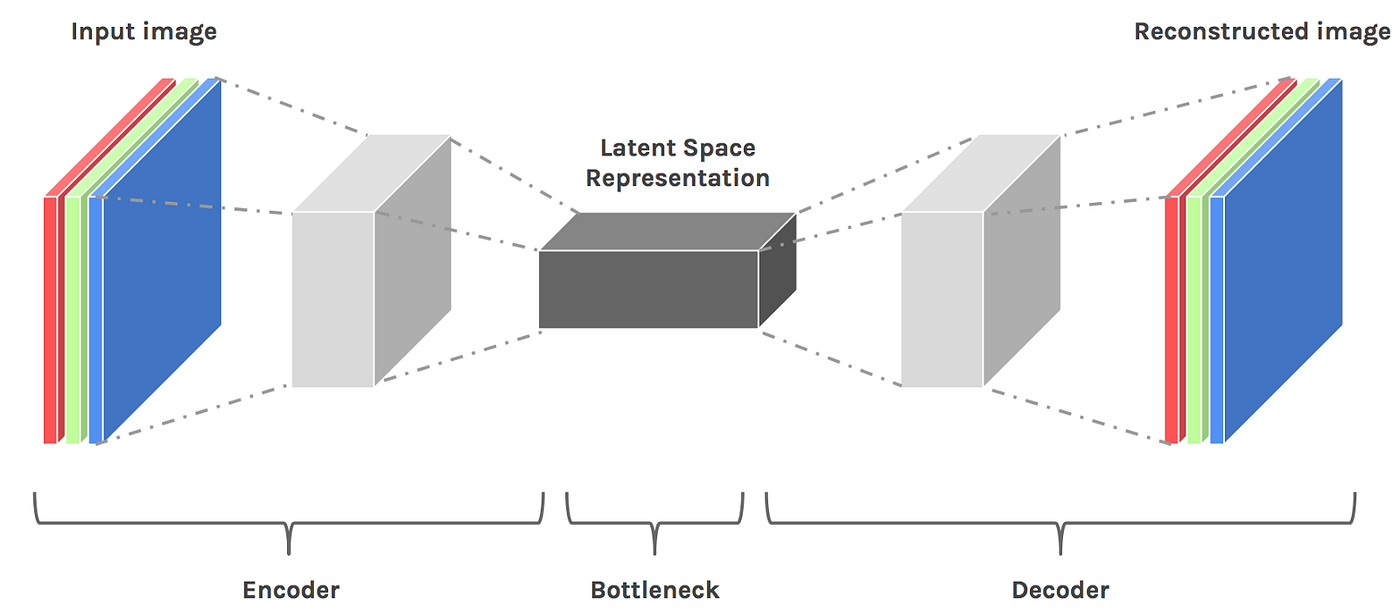
Image Classification Using the Variational Autoencoder | by ...

Variational autoencoder as a method of data augmentation ...
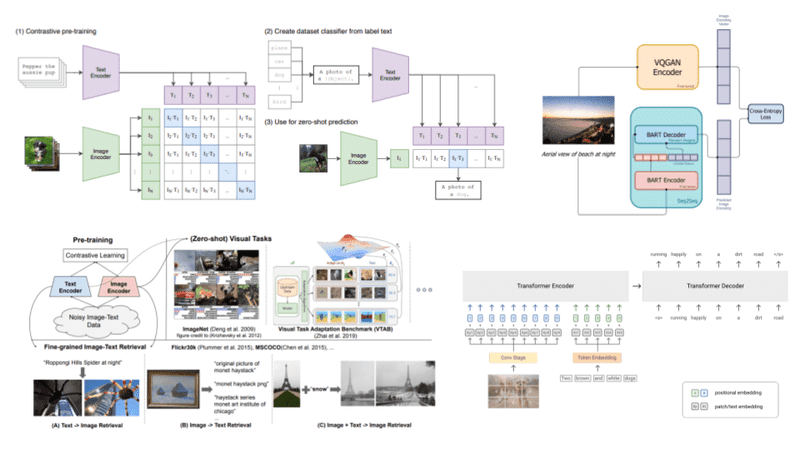
Vision Language models: towards multi-modal deep learning ...
![PDF] Fully Convolutional Variational Autoencoder For Feature ...](https://d3i71xaburhd42.cloudfront.net/a03d73acee093f2c1cf2bb22eecfe1424238ed8b/3-Figure3-1.png)
PDF] Fully Convolutional Variational Autoencoder For Feature ...
Generative modelling using Variational AutoEncoders(VAE) and ...

Anomaly Detection using Autoencoders | by Renu Khandelwal ...

Deep Feature Consistent Variational Autoencoder – arXiv Vanity
![Autoencoders in Deep Learning: Tutorial & Use Cases [2022]](https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/627d121bd4fd200d73814c11_60bcd0b7b750bae1a953d61d_autoencoder.png)
Autoencoders in Deep Learning: Tutorial & Use Cases [2022]
Variational Autoencoder Applications
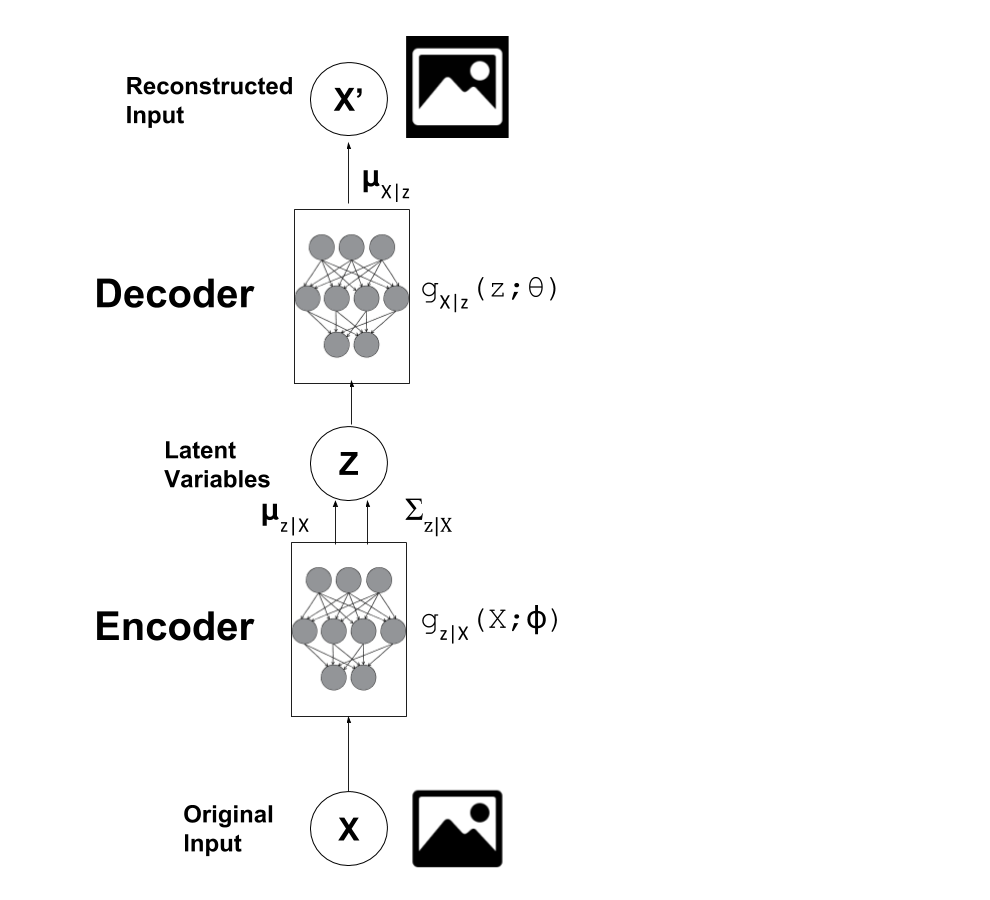
Semi-supervised Learning with Variational Autoencoders ...
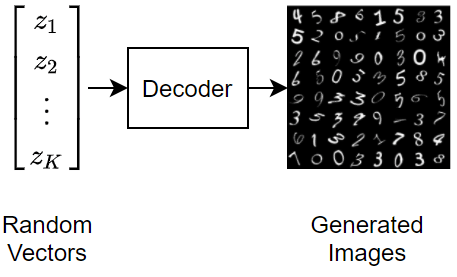
Train Variational Autoencoder (VAE) to Generate Images ...

Introduction to AutoEncoder and Variational AutoEncoder(VAE)

Variational autoencoders | Python Deep Learning - Second Edition

Application of domain-adaptive convolutional variational ...
Esophageal optical coherence tomography image synthesis using ...
Variational Autoencoder Applications
Post a Comment for "38 variational autoencoder for deep learning of images labels and captions"